1、代码中尽量避免group by函数,如果需要数据聚合,group形式的为rdd.map(x=>(x.chatAt(0),x)).groupbyKey().mapValues((x=>x.toSet.size)).collection() 改为 rdd.map(x=>(x.chatAt(0),x)).countByKey();或进行reduceByKey,效率会提高3倍。
2、parquet存储的文件格式查询会比sequenceFile快两倍以上,当然这是在select * from的情况下,但其实100+列的情况下,我们做数据分析很少用到select * ,那么parquet列式存储会更加高效,因为读取一个Parquet文件时,需要完全读取Footer的meatadata,Parquet格式文件不需要读取sync markers这样的标记分割查找。
3、spark.rdd.compress 参数,个参数决定了RDD Cache的过程中,RDD数据在序列化之后是否进一步进行压缩再储存到内存或磁盘上。当然是为了进一步减小Cache数据的尺寸,如果在磁盘IO的确成为问题或者GC问题真的没有其它更好的解决办法的时候,可以考虑启用RDD压缩。
4、spark.shuffle.manage 我建议使用hash,同时与参数spark.shuffle.consolidateFiles true并用。因为不需要对中间结果进行排序,同时合并中间文件的个数,从而减少打开文件的性能消耗。
5、首先,shuffle过程,与result过程都会将数据返回driver端,JVM参数过少会导致driver端老年代也塞满,容易full GC,同时会经常发生GC,因为核数少,所以每个核可以承载更多的数据,那么一下子返回给driver,就塞满新生代,发生GC。监控页面就发现GC time比多核的要高。
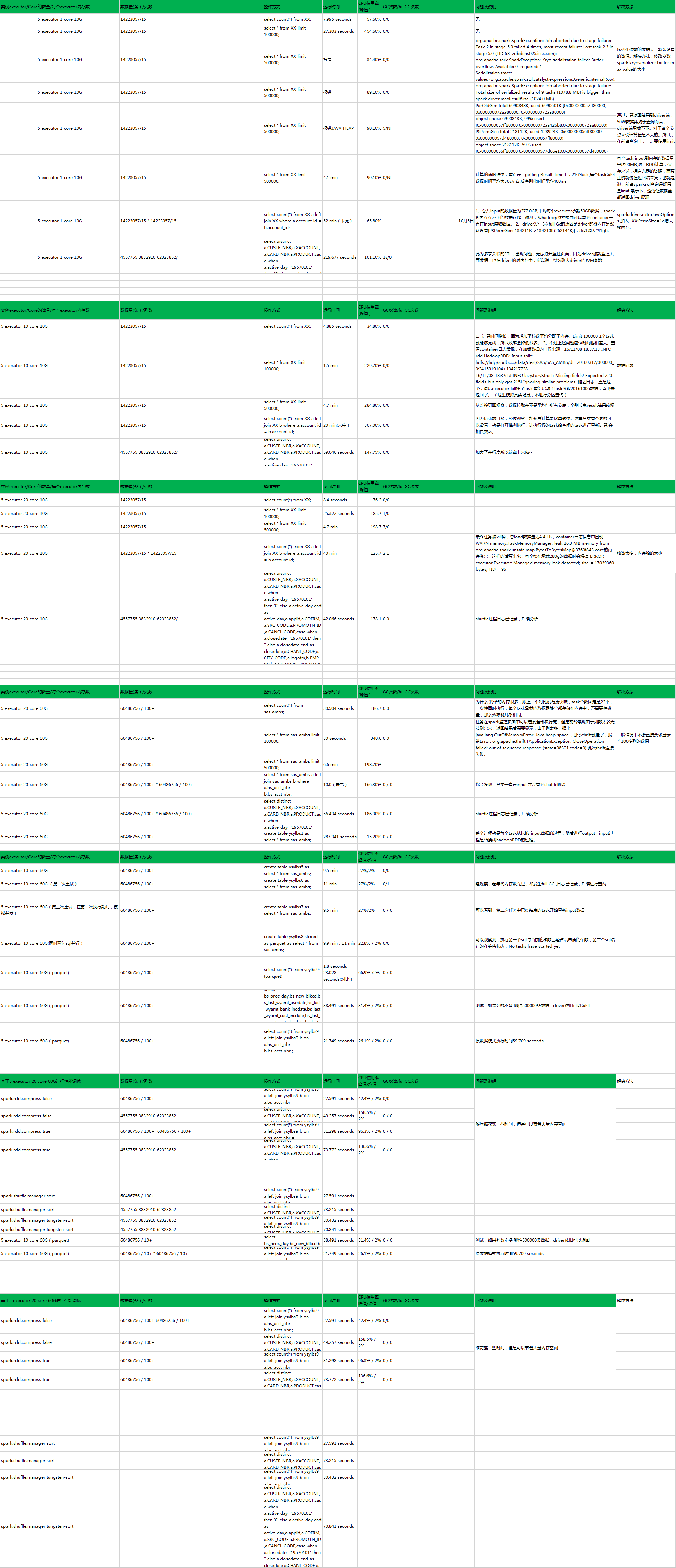
6、这里的limit是直接limit全表的,并没有做where分区limit。 同时left join自关联,即便内存不够的情况下,spark依旧会写入磁盘,但任务相当的慢。
7、发现我们的数据基本没有分库,最好分一下库,如果以后多个部门使用,那么在default中进行各部门数据的梳理生成,最终生成到不同的库中,防止数据杂乱无章。
8、分表,我们现在的数据是按dt字段分区的,没有分表,如果前台查询没有分区,将会造成OOM。 是否可以按照table_name_20161108这种方式,按日生成,那么select * from tablename 也不会造成Spark卡死,其他任务等待。
9、在一个executor实例中,多核会拉起多个task同时并行计算,会比单核计算要快很多。后续用例调整参数,增加与生产同等配置的情况下再进行测试。
10、注意一点,spark监控页面与driver端共享监控页面,可以去查看各个节点containner的运行情况,尽量少的直接点进去看DAG或task运行情况,否则大的任务task数据展示,也是容易导致JVM对内存溢出。
11、CPU瞬时的使用率大概在100-200%左右,最高持续6秒,随后降至百分之2%左右
12、并发极端的情况还未完全测试,但以spark的原理,倘若第一个任务没有占满spark的总并发数,那么另一个任务将会在这些空闲的task中进行轮训执行。 整个调度由DAG控制。
13、spark.speculation true 推测执行,这个参数用来比如有数据倾斜或者某个task比较慢的情况下,会另起一个task进行计算,哪个先完成就返回哪个结果集。但是在spark1.3版本的时候,有中间tmp文件缺失的情况,会报找不到hdfs路径下的文件。所以,推测执行这个参数不知道在spark1.6是否修复,后续进行测试。
14、spark.task.maxFailures 10 这个参数的作用主要是在task失败的情况之下,重试的次数,超过这个次数将会kill掉整个job 这种情况比如网络IO fetch数据失败等情况。
15、spark.storage.memoryFraction 0.5 这个参数 考虑稳定性GC与效率问题,决定使用0.5这个参数。
16、spark.sql.shuffle.partitions 200 经测试修改到400并没有变得更快,是因为给的内存足以进行task的计算,在具体情况下代码中set。
17、spark.kryoserializer.buffer.max 数据传输序列化最大值,这个通常用户各服务器之间的数据传输,这里给到最大10g
18、spark.default.parallelism 3 可使一个core同时执行2-3个task,在代码中通过传入numPartitions 参数来改变。(还需深入测试)
19、spark.reducer.maxSizeInFlight 128M 在Shuffle的时候,Reducer端获取数据会有一个指定大小的缓存空间,如果内存足够大的情况下,可以适当的增大缓存空间,否则会spill到磁盘上影响效率。因为我们的内存足够大。
20、spark.shuffle.file.buffer 128M ShuffleMapTask端通常也会增大Map任务的写磁盘的缓存